

Introduction to SEO (Search Engine Optimization) | What is SEO? | Why SEO is important? | What are Web Crawlers?
My first blog/article for our SEO series. We will talk about SEO, it's importance, and further more on upcoming blogs/articles.



SEO stands for Search Engine Optimization. The goal of SEO is to create a strategy that will increase your rankings position in search engine results. The higher the position, the more organic traffic to your site, which ultimately leads to more business for you!
Why is SEO so important?
SEO is the key to increased conversion and confidence in your brand. Higher search ranking placement equates to more organic visitors. Search engine organic traffic – visitors who come to your site through clicking a result in a search engine – is key to many businesses for three reasons:
- Qualitative – The increased chance that visitors turn into customers.
- Trustable – Higher confidence in your brand or mission.
- Low-Cost – Aside from the time and effort spent, having good SEO practices that result in higher search engine ranking is free. There is no direct cost to appear in top organic search results positions.
Search engine optimization is different from Search Engine Marketing (SEM), where the content at the top of search results is 100% paid and distinguished from organic results with a Sponsored label.
Three Pillars of SEO Optimization
The process of optimizing a website can be divided into three main pillars:
- Technical – Optimize your website for crawling and web performance.
- Creation – Create a content strategy to target specific keywords.
- Popularity – Boost your site's presence online so search engines know you are a trusted source. This is done through the use of backlinks – third-party sites that link back to your site.
Search Systems
Search Systems are what you typically refer to as Search Engines (Google, Bing, DuckDuckGo, etc). They are massively complex systems that tackle some of the biggest challenges in technology history.
Search Systems have four main responsibilities:
- Crawling – the process of going through the Web and parsing the content in all websites. This is a massive task as there are over 350 million domains available.
- Indexing – finding places to store all of the data gathered during the crawling stage so it can be accessed.
- Rendering – executing any resources on the page such as JavaScript that might enhance the features and enrich content on the site. This process doesn't happen for all pages that are crawled and sometimes it happens before the content is actually indexed. Rendering might happen after indexing if there are no available resources to perform the task at the time.
- Ranking – querying data to craft relevant results pages based on user input. This is where the different ranking criteria are applied in Search engines to give users the best answer to fulfill their intent.
What are Web Crawlers?
Web crawlers are a type of bot that emulate users and navigate through links found on the websites to index the pages. Web crawlers identify themselves using custom user agents. Google has several web crawlers, but the ones that are used more often are Googlebot Desktop and Googlebot Smartphone.
For your website to appear in search results, Google (as well as other search engines such as Bing, Yandex, Baidu, Naver, Yahoo, or DuckDuckGo) use web crawlers to navigate the website to discover websites and its web pages. Different search engines have different market shares in each country. While there are some differences when it comes to Ranking and Rendering, most search engines work in a very similar way when it comes to Crawling and Indexing.
How Does Googlebot Work?
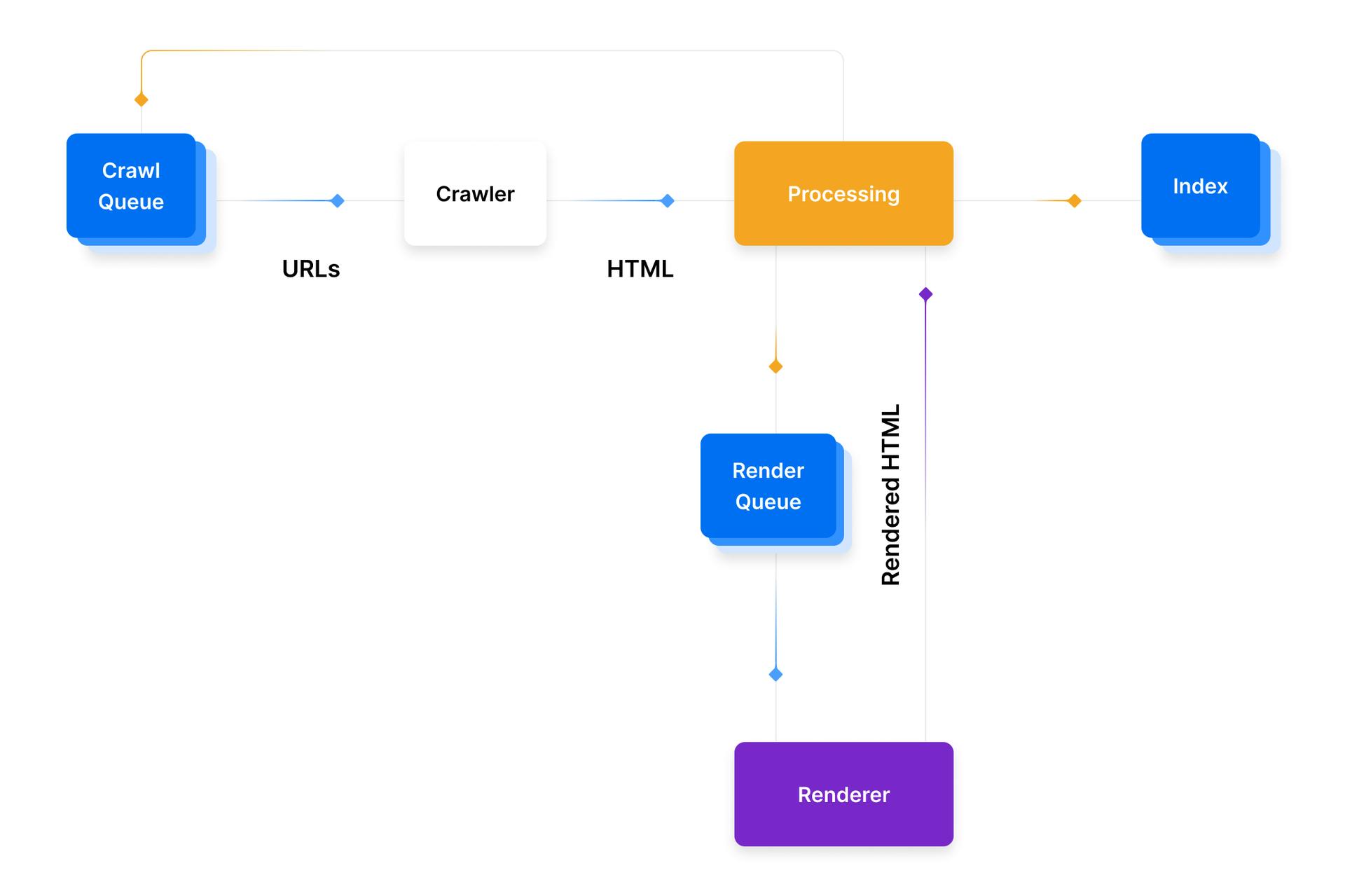
A general overview of the process can be the following:
Find URLs: Google sources URLs from many places, including Google Search Console, links between websites, or XML sitemaps.
Add to Crawl Queue: These URLs are added to the Crawl Queue for the Googlebot to process. URLs in the Crawl Queue usually last seconds there, but it can be up to a few days depending on the case, especially if the pages need to be rendered, indexed, or – if the URL is already indexed – refreshed. The pages will then enter the Render Queue.
HTTP Request: The crawler makes an HTTP request to get the headers and acts according to the returned status code:
- 200 - it crawls and parses the HTML.
- 30X - it follows the redirects.
- 40X - it will note the error and not load the HTML.
- 50X - it may come back later to check if the status code has changed.
Render Queue: The different services and components of the search system process the HTML and parse the content. If the page has some JavaScript client-side-based content, the URLs might be added to a Render Queue. Render Queue is more costly for Google as it needs to use more resources to render JavaScript and therefore URLs rendered are a smaller percentage over the total pages out there on the internet. Some other search engines might not have the same rendering capacity as Google.
Ready to be indexed: If all criteria are met, the pages may be eligible to be indexed and shown in search results.
Conclusion
These were the basics of SEO, Web crawlers, and GoogleBot. Everything we have talked about today will create a foundation for future big topics. Let me know if I missed something.
Thank you for reading my blog/article. ❤️❤️