

Crawling and Indexing | Search Engines Basics
Let's deep-dive into several key parts that impact Crawling and Indexing for SEO (Search Engine Optimization)



This is the second article for my SEO series. Scroll bottom to see the lists.
What is Crawling?
Crawling is a process which is done by search engine bots to discover publicly available web pages.
What is indexing?
Indexing means when search engine bots crawl the web pages and saves a copy of all information on index servers and search engines show the relevant results when a user performs a search query.
There are multiple factors that impact Crawling and Indexing. We will see them in detail.
- HTTP status code
- robots.txt
- XML Sitemaps
- Special Tags
- Canonical Tags
What are HTTP status codes?
HTTP response status code indicate whether a specific HTTP request has been successfully completed. There are many status codes, but only a handful are meaningful in an SEO content. Let's take a look at them.
200
The
HTTP 200 OKsuccess status response code indicates that the request has succeeded.In order for a page to be indexed on Google, it must return status code
200. This is what you typically want to look for in your pages in order for them to receive organic traffic.301/308
The
HTTP 301 Moved Permanentlyredirect status response code indicates that the resource requested has been definitively moved to the destination URL.This is a permanent redirect. In general, this is the most widely used redirect type.
Redirects can be used for a variety of reasons, but the main one is to indicate that a URL has been moved from point A to point B. Redirects are needed to ensure that, if a content is moved from one place to the other, you do not lose current and potential clients and the bots can continue to index your site.
The main difference between the two status codes it that a
301allows for changing the request method fromPOSTtoGET, whereas a308does not.302
The
HTTP 302 FOUNDredirect status response code indicates that the resource requested has been temporarily moved to the destination URL.In most cases,
302redirects should be301redirects. This may not be the case if you are redirecting users temporarily to a certain page (e.g. a promotion page) or if you are redirecting users based on location.404
The
HTTP 404 Not Foundclient error response code indicates that the server can't found the requested resource.As noted above, pages that are moved should be redirected with a
HTTP 301status code to the new location. When this doesn't happen, URLs may return a404status code.404Status Codes are not necessarily bad by default, as it's the desired outcome if a user happens to visit a URL that doesn't exists, but they shouldn't be a frequent error within your pages as it could lead to lackluster search rankings.410
The
HTTP 401 Goneclient error response code indicates that access to the target resource is no longer available at the origin server and that this condition is likely to be permanent.This is not used very often, but you might want to look for this status code if you are deleting content on your website that won't exist any more.
Examples where a
HTTP 401 Gonemight be wise to use include:- E-commerce: Products permanently removed from inventory.
- Forum: Threads that have been deleted by the user.
- Blog: Blog post removed from site.
This status code informs bot that they should never return to crawl this content.
500
The
HTTP 500 Internal Server Errorresponse code indicates that the server encountered an unexpected condition that prevented it from fulfilling the request.503
The
HTTP 503 Service Unavailableserver error response code indicates that the server is not ready to handle the request.It's recommended to return this status code when your website is down and you predict that the website will be down by an extended period of time. This prevents losing rankings on a long-term basis.
What is a robots.txt File?
A robots.txt file tells search engine crawlers which pages or files the crawler can or can't request from your site. The robots.txt file is a web standard file that most good bots consume before requesting anything from a specific domain.
You might want to protect certain areas from your website from being crawled, and therefore indexed, such as your CMS or admin, user accounts in your e-commerce, or some API routes.
These files must be served at the root of each host, or alternatively you can redirect the root /robots.txt path to a destination URL and most bots will follow.
Why do you need robots.txt?
robots.txt files control crawler access to certain areas of your site. While this can be very dangerous if you accidentally disallow Googlebot from crawling your entire site (!!), there are some situations in which a robots.txt file can be very handy.
Some common use cases include:
Preventing duplicate content from appearing in SERPs (note that meta robots is often a better choice for this. We will see down below soon).
Keeping entire sections of a website private (for instance, your engineering team’s staging site).
Keeping internal search results pages from showing up on a public SERP.
Specifying the location of sitemap(s).
Preventing search engines from indexing certain files on your website (images, PDFs, etc.).
Specifying a crawl delay in order to prevent your servers from being overloaded when crawlers load multiple pieces of content at once.
Important things to remember about robots.txt
In order to be found, a
robots.txtfile must be placed in a website’s top-level directory.robots.txtis case sensitive: the file must be namedrobots.txt(not Robots.txt, robots.TXT, or otherwise).The
/robots.txtfile is a publicly available: just add/robots.txtto the end of any root domain to see that website’s directives (if that site has arobots.txtfile!). This means that anyone can see what pages you do or don’t want to be crawled, so don’t use them to hide private user information.Each subdomain on a root domain uses separate
robots.txtfiles. This means that bothblog.example.comandexample.comshould have their ownrobots.txtfiles (atblog.example.com/robots.txtandexample.com/robots.txt).It’s generally a best practice to indicate the location of any sitemaps associated with this domain at the bottom of the
robots.txtfile. Here’s an example:
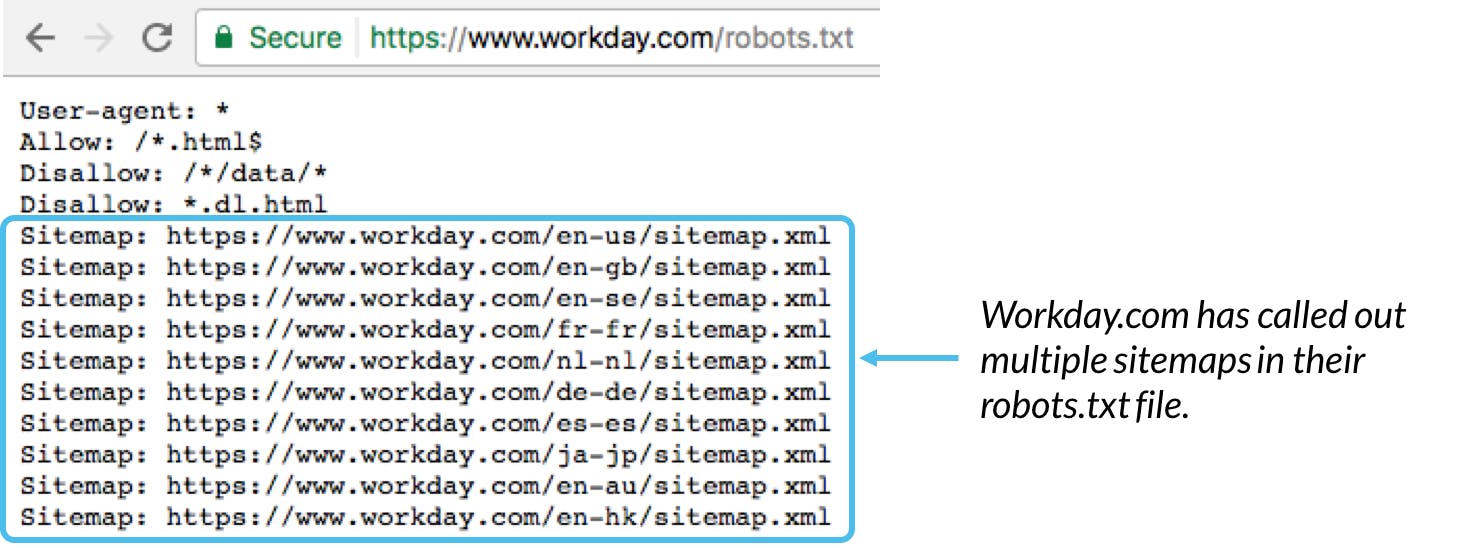
Some common robots.txt syntax
There are five common terms you're likely come across in a robots file. They include:
user-agent: The specific web crawler to which you're giving crawl instructions (usually a search engine). A list of most user agents can be found here.
disallow: The command used to tell a user-agent not to crawl particular URL. Only one
disallow:line is allowed for each URL.allow (Only applicable for Googlebot): The command to tell Googlebot it can access a page or sub-folder even though its parent page or sub-folder may be disallowed.
crawl-delay: How many seconds a crawler should wait before loading and crawling page content. Note that Googlebot does not acknowledge this command, but crawl rate can be set in Google Search Console.
sitemap: Used to call out the location of any XML sitemap(s) associated with this URL. Note this commend is only supported by Google, Ask, Bing, and Yahoo.
Some common useful robots.txt rules. learn here.
Pattern-matching
When it comes to the actual URLs to block or allow, robots.txt files can get fairly complex as they allow the use of pattern-matching to cover a range of possible URL options. Google and Bing both honor two regular expressions that can be used to identify pages or subfolders that an SEO wants excluded. These two characters are the asterisk (*) and the dollar sign ($).
- * is a wildcard that represents any sequence of characters.
- $ matches the end of the URL.
Google offers a great list of possible pattern-matching syntax and examples here.
Examples of robots.txt
Just enter domain/robots.txt and you will see the file, if it exists.
XML Sitemaps
Sitemaps are the easiest way to communicate with Google. They indicate the URLs that belong to your website and when they update so that Google can easily detect new content and crawl your website more efficiently.
Even though XML Sitemaps are the most known and used ones, they can also be created via RSS (Really Simple Syndication) or Atom or even via Text files if you prefer maximum simplicity.
A sitemap is a file where you provide information about the pages, videos, and other files on your site, and the relationships between them. Search engines like Google read this file to more intelligently crawl your site.
According to Google:
You might need a sitemap if:
Your site is really large. As a result, it's more likely Google web crawlers might overlook crawling some of your new or recently updated pages.
Your site has a large archive of content pages that are isolated or not well linked to each other. If your site pages don't naturally reference each other, you can list them in a sitemap to ensure that Google doesn't overlook some of your pages.
Your site is new and has few external links to it. Googlebot and other web crawlers navigate the web by following links from one page to another. As a result, Google might not discover your pages if no other sites link to them.
Your site has a lot of rich media content (video, images) or is shown in Google News. If provided, Google can take additional information from sitemaps into account for search, where appropriate.
While sitemaps are not mandatory for great search engine performance, they can facilitate crawling and indexing to bots and hence your content will be picked up faster and rank accordingly.
It's strongly recommended to use sitemaps and make them dynamic as new content is populated across your website. Static sitemaps are also valid, but they might be less useful to Google as it won't serve for constant discovery purposes.
Special Meta Tags for Search Engines
Meta robot tags are directives that search engines will always respect. Adding these robots tags can make the indexation of your website easier.
There is a difference between directives and suggestions. Meta robot tags or robots.txt files are directives and always be obeyed. Canonical tags are recommendations that Google can decide to obey or not.
There are many options when it comes to page level meta tags, but the following are examples that commonly associated with SEO:
<meta name="robots" content="noindex, nofollow" />
The robots tags is probably the most common tag you will see. By default it will have the value index, follow so it does not need to be specified, all is also a valid alternative version:
<meta name="robots" content="all" />
By setting a robots tag to noindex, nofollow as in the example above, it will indicate to search engines:
noindex
To not show this page in search results. Omitting
noindexwill indicate the page can be indexed and shown in search results.When building a website, you might not want to index certain pages. Common use cases include settings pages, internal search pages, policies, and more.
nofollow
To not follow links on this page. Omitting this will allow robots to crawl and follow links on this page. Links found on other pages may enable crawling, so if
link Aappears in pagesXandY, andXhas anofollowrobots tag, butYdoesn't, Google may decide to crawl the link.
Note: You can see a full list of directives in the Google official documentation.
Googlebot tag
<meta name="googlebot" content="noindex, nofollow" />
You may also see the googlebot tag sometimes. In most cases the robots is all you will need. The googlebot tag is specific to Google. Use this tag if you want to have a separate rule for Googlebot, and a general one for the rest of the search bots.
In the case there is conflicting tags, the more restrictive tag applies.
You may be wondering why we need these tags if you can add URLs to your robots.txt that you do not want crawled. The meta tag gives you flexibility to mark pages as noindex on demand.
For example, if you apply filters to a product page and you end up with no results, it would be common practice to noindex this page.
URLs that are restricted from bots crawling via robots.txt file will never be crawled by Google, but if the rules are added after pages are already indexed, pages might remain indexed. The best way to make sure that a page is no indexed is using the noindex tag.
Note: Google can decide to index a page without crawling it. This is extremely rare, but happens when Google wants a page to fulfill a specific search result and has certainty that the page contains what users expect.
Google tags
nositelinkssearchbox
<meta name="google" content="nositelinkssearchbox" />
When users search for your site, Google Search results sometimes display a search box specific to your site, along with other direct links to your site, this tag tells Google not to show the sitelinks search box.
notranslate
<meta name="google" content="notranslate" />
When Google recognizes that the site contents are not in the language that the user is likely to want to read, Google often provides a link to a translation in the search results.
In general, this gives you the chance to provide your unique and compelling content to a much larger group of users. However, there may be situations where this is not desired. This meta tag tells Google that you don't want them to provide a translation for this page.
What are Canonical Tags?
A canonical URL is the URL of the page that search engines think is most representative from a set of duplicate pages on your site.
While you can directly communicate canonical URLs to search engines, they can also decide to group several URLs without you notifying it. This might happen automatically if Google can find a URL under several different paths.
While Google does a great job at detecting those, their systems work at massive scale and don't cover all edge cases. Canonical tags are an important aspect to cover for your website to ensure great performance.
If Google finds several URLs that have the same content, it might decide to demote them in search results because they can be considered duplicated.
This also happens across domains, if you run two different websites and post the same content in each one, search engines can decide to pick one of them to be ranked, or directly demote both.
This is where canonical tags are extremely useful. They let Google know which URLs are the original source of truth and which are duplicated. Lots of duplicated pages across same or different domains can lead to bad rankings or even penalizations.
Let's imagine that our e-commerce shop allows products to be accessible via example.com/products/phone and example.com/phone.
Both are valid, working URLs, but we use canonical to prevent the detection of duplicate content that we own. If we decided that https://example.com/products/phone should be considered for rankings, we would create a canonical tag:
<link rel="canonical" href="https://example.com/products/phone" />
Canonical tags are fundamental in SEO performance, because not only can you create different URLs, but users or marketing tools can also create them.
Imagine that you are running some marketing campaigns on Google, then Google decides to add some UTM parameters. It's possible that this new, unique URL will be indexed by Googlebot so you want to be sure you are still showing your canonical tags to unify duplicate pages.
Conclusion
These were the factors that will highly impact the Crawling and Indexing of our websites. By using these basic SEO techniques, our website ranking will make a big difference. Let me know if I missed something.
Thank you for reading my blog/article. ❤️❤️